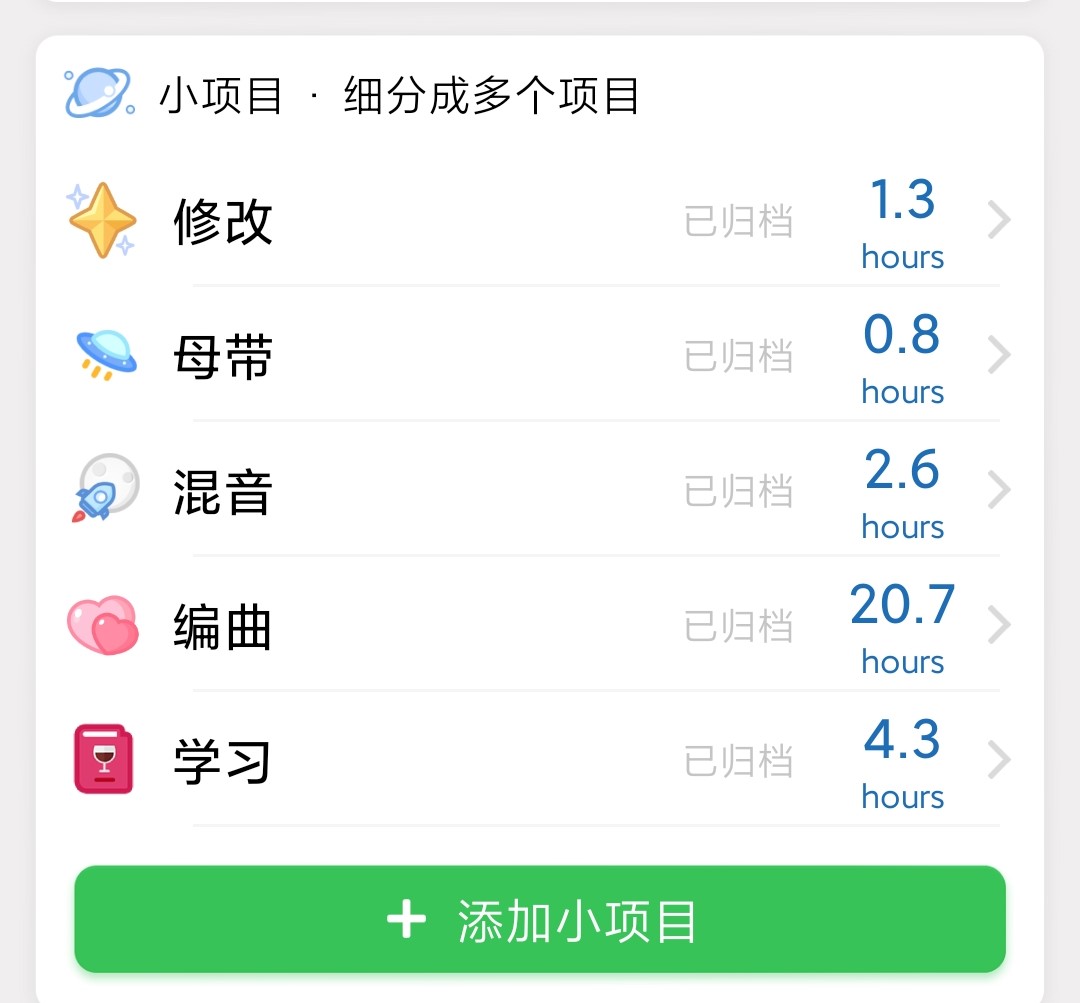
from maki
酒吧驻唱初体验(下)
3.5 补充一些排练细节
上篇忘了说,七点多的时候,贝斯手来了。他的气质就蛮符合我对贝斯手的刻板印象,就什么都淡淡的,不怎么说话但你不会觉得他冷漠或者害羞,他只是不怎么说话而已。
琴包的顶上挂着一个毛茸茸的挂件,一晃一晃的。发型算是短发里面比较长的,显得柔和一些(忍不住拿他跟吉他手比较)。
看到他来了,我就唱完然后说贝斯老师要不要一起。
因为舞台太小了,我的左边右边都有人,他就只能坐在我正后面,跟吉他手挨着。
(也许这个酒吧在设计装修的时候就没打算让这样编制的乐队来吧……太拥挤了,一台电鼓就几乎占了舞台的一半。吉他手居然坐在台下,贝斯手坐在墙根,他俩挡住了本就很窄的出入口。其他人想上台用另一个麦克风唱歌的时候,直接像玩跳马游戏那样从桌子上骑着翻上舞台。现在想来觉得十分滑稽。不过当晚滑稽的事实在太多,这个排不上号了。)
贝斯手掏出一张手写的歌单,白纸黑字的,上面写着歌名和调。现在回忆起那张纸的配色,我觉得太素了,有点凄凉,给人一种办白事的感觉。
我也带了自己写的歌单,是用的书慧的拍纸本,彩色的,笔也是彩色的。单纯是因为纸和笔买太多了用不完。
印象中我们是先顺着歌单继续往后排,然后又回到最前面从第一首开始(记忆有点模糊了)。总之贝斯手的淡定程度不输给吉他手,他就跟吉他手说了句下行是不是,然后他俩就弹起来了。
我觉得很有意思可以观察到乐手是怎么交流的,虽然也没有太听懂。大概是和弦根音一直往下走吧。但贝斯手是怎么知道的呢,他是扒过原曲,还是听的吉他手的和弦所以这样判断呢……
不过当时没时间想这些更没时间问。
排得差不多了主理人说大家休息一下吧,然后贝斯手就出去买吃的了,过了一会拿着一根糯玉米回来啃。我从台上下来在旁边椅子坐着喝自己带的水。
吉他手没有挪窝,跟鼓手说了个啥,你随便打。大概是想即兴练习吧,鼓手就即兴打,然后吉他手即兴弹。
不知道是鼓手会的少还是年轻人就是躁啊,吉他手弹一些比较chill的东西的时候,鼓手还在那里动次打次动次打次动动动动…………听得我有点烦。而且好几次,他俩收尾的时候没对上,和弦听起来要结束了,鼓手还在那里激情四射打个没完。
就算是临时的草台班子打着玩也要配合队友的嘛!
但有没有一种可能,鼓手根本听不见吉他手弹的啥?有可能。不过这些都是我后来想到的,当时我就在那里呆呆地喝水而已。
主理人说第一趴结束后去吃饭,我还想了想到时候要不要一起去,因为我包里还揣着个汉堡。下午出门前点了俩,吃一个带一个。
我还是决定跟他们一起去吃饭,因为我想听他们聊天,多获取一些信息。顺便蹭个饭,这样汉堡可以留到明天当早饭。
对了,排练的时候,排到《简单爱》,主理人说他也想唱,于是上来跟我对唱一番,后来他还唱了《静止》。唱得,不好听也不难听吧。。。精神头倒是挺足的。看着空荡荡的台下,我想这样也挺好,我巴不得歇会。
4.第一趴演出
上篇忘了讲一个重要的问题,就是上台紧张的问题。
这个问题也蛮有意思的,很多时候你其实并不紧张,你就照常表现,然后突然脑子想到了我会不会紧张的问题,然后你才紧张了。声音抖了一下,或者觉得没气了,被自己听到了,心想,啊,我紧张了,我果然紧张了……!
现在想来,那晚确实有好多次这样的时刻。不过总体来说,我觉得我虽然有点紧张,但它并不是影响我表现的主要因素。
影响我表现的主要因素还是,一、我的基本功感人(贬义);二、返听太垃圾。
假如你是站在讲台上的老师,那个返听的感觉就好像是,它是从教室最后面的黑板报上传来的,而且上面还蒙着一层破床单。
不说这个了,希望以后有机会用上耳返吧……
没休息多久就到了八点钟,我感觉我又紧张了,心理上对排练和演出还是有些区分的,觉得演出更严重,更可怕一些。
但因为没有顾客,所以其实,没有任何区别。
我对酒吧的经营完全不了解,但常识告诉我一个酒吧在周日晚上八点钟如果一桌客人都没有,那不是什么积极信号。
(其实在大众点评看评论的时候就有心理准备了。而且,我衷心认为这个酒吧没生意跟它的装修有很大关系。我都不好意思放图,太丑。那附近怎么说也是传媒类企业集中的地方,高碑店啊家人们,你装成那样到底想吸引什么样的客群……)
第一趴演出本身倒没太多可说的,算是比较顺吧,顺到我会时不时走神。嘴巴自动唱着,脑子却一飘一飘的,一时间甚至冒出一个念头:你看我在这里胡思乱想,但歌声还是不受影响哎(……我简直要怀疑这是不是某种程度的解离)。
而且,我根本听不到贝斯的声音……吉他也几乎听不到,自己的声音也很遥远,倒是鼓很吵。
我是谁,我在哪,我在干嘛,这都是谁……?
不过,跟乐队一起演,真的乐器,还是比伴奏要爽的……那种临场感,好像刚炸出来的炸鸡,刚炒出来的带着锅气的炒粉……某些段落吉他手或者鼓手会说给对方听,比如“再来最后一遍!”什么的,然后真的能一起结束,好像是个很默契的团队似的,草台班子评分减一分(。)
我忍不住想象如果是认真编的歌、而不是套路的和弦、如果有认真排练过、而不是现场对付、如果是自己的歌、完整的有诚意的表演……
当时顾不得想这些,只觉得懵懵的。其实很多感受是一边回忆一边冒出来的,比如,通惠河上面的同心桥,好像一根大油条……
之前听过很多老哥他们团的访谈,这次体验过之后,对他们说过的话有了一些新的认知……
比如,这个吉他手(指老哥)好厉害,我要跟他组团!——是一种什么心情(并不是说我想跟这个吉他手组团,事实上当晚的乐手0人让我想跟他组团。我学到的是,原来想不想跟一个乐手组团的心情是如此明确。不过,我在judge他们的时候,他们也在judge我吧。好吧,其实贝斯手还可以考虑,原因竟是:因为他表现得少,所以扣分也少……考虑啥啊他连排练都来那么晚);
比如,小朱(老哥的贝斯手)说的,我们那时候唱一家倒一家——我看这家也快倒了……
第一趴很快唱完了,于是一群人去吃饭。贝斯手走下台,掏出玉米继续啃。
其他人在前面先走了,我觉得把贝斯手晾在那不太好吧(不确定有没有人招呼过他),就主动跟他说,你一个人在这儿吃玉米呀?他看着我,淡淡点头。
(如果我确定其他人有跟他说过我们去吃饭了之类的话,我就不会跟他说话了。单纯是不想他被冷落了。我真是一个大好人(:з)∠))
现在回忆起来,感觉贝斯手一整晚都只有一个表情,一个宠辱不惊的智慧的似笑非笑的圆润的表情,即使是啃玉米时也不曾改变。不过大部分时间我看不见他的表情,因为我的后脑勺没长眼睛(。)
5.在拉面馆吃饭
酒吧附近走过一个转角就是一家拉面馆,晚上八点半,顾客不多。我们从酒吧去拉面馆的路上也没看见几个人,路上很萧条的样子。那附近就是那种北京的园区的气质,地方看起来挺宽敞,但商业稀疏,人气也聚拢不起来的感觉。我想,也许没客人跟这个选址也有些关系。
走进去之后,主理人说大家看看吃什么。大家都来碗拉面,我说我也一样。
店里灯光很亮,典型的快餐感觉,菜单是那种墙上挂的灯箱,十分刺激感官。我根本没脑子看菜单也没心情点菜,事实上当时的我连看汉字都费劲,几个字的菜名看完不知道什么意思。
点完拉面大家坐下,此时小绿也在,坐在我旁边。吃饭时聊的内容大部分在上篇已经提过,这里只补充一些。
黑衣男的话题好像是鼓手先提起来的,他说那个人指了他好几次。(我完全没发现)听鼓手这么说我才意识到,原来黑衣男不止对我不满意,还对鼓手不满意。
虽然我也对鼓手不太满意,但我觉得他没有很大问题。我对黑衣男的表现充满了疑惑,至于吗哥们,你很了不起啊。
主理人说穿牛仔服的男的是老板的弟弟,不是老板本人。
(后来,牛仔男有自己上台唱歌。我在大众点评也有看到顾客说老板唱歌很好听。所以我不知道顾客们说的唱歌好听的是牛仔男还是他哥,又或者他们兄弟俩都会唱歌。但我更想知道的是,装修到底是谁拍的板……)
牛肉面很久才上来,可能是现拉的面所以比较慢吧,我都有点不耐烦了。但我并不饿,面上来之后挑了两筷子就吃不下了。
小绿一直在跟其他三个人聊天,嘴巴就没停过。他没有点拉面,他说他吃过饭了(所以他也是抱着社交的心态来吃饭的吧)。过了一会吉他手端来一份烤馕给小绿,小绿说大家一起吃。
聊天的气氛不那么轻松,毕竟情况摆在那。
小绿说还是有顾客的呀,那个穿橙色羽绒服的大哥,还拍视频呢。鼓手说那是我爸,等会接我回家呢。——就连最好笑的一段都带着凄凉。
小绿是一个大e人,别人说啥他都能接下去。我比想象中要累,放空了好几次,自己又把自己拉回来。我走神的时候,小绿在说话,我走神完了回来了,小绿还在说话。
我心想哥们你能不能消停会,高精力人士是这样的吗?刚我还看到他把玩吉他手的吉他来着,估计也是搞音乐的吧。
不过后来多亏了小绿,某种程度上算是救场了。
6. 终于有顾客了
吃得差不多,主理人说那我们回去吧,小绿说看看有人来吗。我又开始紧张了。
回去发现还真有一桌顾客,两男两女,看起来是两对情侣。两位女生看起来就是标准的小红书上面的美丽驻唱歌手打扮,脸小巧精致,长发,化了妆,合身的时尚上衣,小短裙大长腿,一切都是那么地标准美女。
我心想,要不你们上来唱吧。
至于俩男生,看起来就是俩男生,有一个长得有点像好妹妹乐队的张小厚。
其实在来酒吧的路上,下了地铁我就碰到一个类似的大长腿女生,对不起用这样标签化的词语,但就是那种,哎说白了这里是高碑店,时尚时尚最时尚(最时尚可能还得是三里屯)。
当时我心里就咯噔一下子,我知道那样才是一般人心目中驻唱歌手应该有的形象。
想起来之前听一个在唱片公司管理层干过的人的讲座说,你有没有做好准备呢?如果你想当创作歌手,你有没有一年写一两百首歌呢?如果你想有上台的机会,你有没有减肥呢?
台下的我就眨巴眨巴眼试图消化这些信息,但心里又十分抵触,尤其是对于减肥二字……
这个行业是这样,即使你很苗条,你一年写一两百首歌,你也不一定有机会啊。
(所以,要不还是干脆放弃好了。本来就很穷,还不能吃拼好饭,这日子还怎么过啊……)(拼好饭现在也很贵。)
不好意思扯远了。第一趴唱完之后我松了半口气,因为跟吉他手合作对我来说压力挺大的。他那种什么都没准备但云淡风轻甚至来指挥我的气场让我觉得很难对上频率(无论是团队合作的频率,还是他的吉他演奏出来的频率……)。
如前所说,吉他手只待两趴,第三趴我只需要跟伴奏就好了。等于困难的任务已经完成了一半。但顾客的到来,为第二趴增加了一些难度(主要是心理上的)。
好消息是,顾客还挺捧场的,不时抬头看我们,好像还面带微笑(灯光昏暗看不太清),也会鼓掌。
坏消息是,他们一直在抽烟,到后面我嗓子都有点发紧。
好消息是,顾客点了歌。这多少可以视为一种肯定吧。
坏消息是,我不会唱。一首完整会唱的都没有。
早在商量歌单时就跟主理人说过,我应付不了点歌。主理人说没事,那就不点歌。
好消息是,小绿会唱。
其实这里我的记忆又有点错乱,不太记得小绿第一次上来唱是什么时候,在什么情境下。
换句话说,顾客点歌的时候有没有听过小绿,顾客到底是想听我唱,还是想听小绿唱,所以才点了歌,我不太记得了……
顾客先是点了两首,唱完又点了两首。基本上都是小绿在唱,我偶尔能跟着唱两句副歌这样子。小绿唱得不错,后来主理人告诉我说,他有自己的乐队,是主唱来着。(他们乐队的名字也很搞笑…………)
重点是小绿很会互动,每次唱完都说两句吉祥话(吉祥话),还说得挺自然,让人觉得嗯,这是一种基本礼仪。而我就跟着谢谢,谢谢。
他唱的时候我多想下台到旁边坐着啊!!!要不是舞台出入口完全被堵住,我早就识趣地躲起来了。哪怕有个铃鼓让我可以挥一挥也好。啥也没有,我就拍手,拍一会就累了。
顾客点的歌里面我会的最多的是林俊杰(我谢谢你)的 always on line。小绿唱着我就试着一起唱,他get到了会把句子让给我。结果我又不太会,他又赶紧补上。大概就是这样非常临场发挥的感觉。
顾客还点了仙剑三电视剧的歌,有个什么此生不换吧,我听见鼓手嘀咕说怎么打啊……我趁机凑过去说,抒情的,轻一点,慢歌,别太猛(终于把憋了一晚上的话说出来了)。
期间还能看到牛仔服男老板弟弟时不时从吧台端着做好的酒送到顾客桌上,后来他们还玩了一会不知道是骰子还是什么东西的游戏,不过也不吵闹。就是这个抽烟啊,我是真受不了,四个人全在抽烟,一根接一根。
酒吧大概是最不可能室内禁烟的地方了吧。所以我对酒吧驻唱这个职业产生了,更多的抗拒。(虽然它更抗拒我吧)
(所以后来小绿加了我微信说给我推荐机会的时候,我表示出了一些拒绝。)
我和小绿还唱了《闷》,排练的时候他好像就很喜欢这首歌,吉他手说没听过,他还打趣吉他手。(此时顾客还在不在,我已经不记得了)
总之说下面要唱《闷》的时候他就说啊来摇滚一点的!等我反应过来他已经在台上了。很元气,很有活力,我心想有必要吗哥们这么开心吗……这歌需要蹦起来吗?(吃饭的时候听到他说他是98还是99的来着)
之所以要提这首歌是因为吉他手说,我觉得你们俩的声音挺搭的,可以加个联系方式。到时间了吉他手收拾东西要走的时候,又说,你们的声音真的很互补,效果不错的。
然后前略后略,吉他手问我,你是单身吗?
我:啊?(听清楚了但故意啊一下表示无语)
他又问了一遍,全程还是那种严肃的表情,而我快要失去表情管理,因为我有点无语。
我说,单身啊。他说,哦。(?)
总之,小绿是吉他手的司机,排练的时候就听到吉他手说你那个车能不能装下我的吉他啊,啥啥的。所以第二趴结束后,小绿跟吉他手一起走了。鼓手也走了,贝斯手也走了。顾客也走了,本就冷清的场子从冷藏室变成了冷冻室的感觉。
不过我也无所谓,也有点累。主理人说等会第三趴你就唱什么什么,我唱什么什么,然后就结束。我说行(累了,想早点回去了)。我让他找牛仔男要放伴奏用的平板。
坐着休息的时候,我很恍惚。也可能是二手烟的缘故。
想到小绿唱的点歌,心想,真的是99一首吗?不管是不是,不管多少钱,这个钱应该他拿吧。我是没什么贡献。
不过时至今日,写这篇blog的现在,我也没收到一分钱。说是分酒水来着,估计酒水也没多少钱,老板肯定是亏的,搞不好完全没给主理人钱也说不定。毕竟黑衣男都当面那样了(让我们把最讨厌的人的奖杯颁给他🏆)。
我知道我应该问一问钱的事,但我完全不想问。也许大家看到这里,多少可以理解我的心情。
7.令人神游的第三趴
小绿是什么时候回来的,我已经不记得了。你来唱吧,我好累。这就是我全部的心情。
(需要补充的是,某一趴的时候,音箱不知道怎么地啸叫了好几次(就是那种很刺耳的声音),我只好唱的时候离麦克风远一点。余光看到小绿在跟我比划,让我的手不要扶着麦克风,我就照做了。好像还是有点啸叫,但有变轻一点。这让我有点感谢小绿。)
(小绿碰到喜欢的歌还会跟唱,吉他手好像也会,他俩坐一起我分不清楚是谁的声音。但这么一唱,我就更听不见我自己的声音了……)
第三趴的开始,是牛仔男唱的。他说,给我演示一下平板怎么用。然后就自己唱起来了。我心想一个平板有什么不会用的,又不是海底捞点菜呢。打开全民K歌播放不就完了。
结果只是他自己想过过瘾而已。反正也没有顾客。
他唱了好几首经典民谣老登歌曲,安河桥,成都,还有个什么忘记了。
说实话唱得还不错,虽然没什么个性。
想一想一整晚他好像也没有表现出太多对我们的敌意。小绿非常捧场,又是鼓掌又是夸奖的。主理人也是。我虽然坐在牛仔男的身后他看不见的地方,但也鼓掌以示尊重……心想,哥们唱完了吗怎么还不下来。
突然想起流年(香油)发嘟说对架子鼓有点兴趣但太占地方,就录视频给她看电鼓的样子。(电鼓还是很占地方!)
牛仔男说他十几年前唱歌还行,现在倒嗓了。小绿说哪有哪有,唱得很好啊。
我心想,是当驻唱歌手攒了一笔钱然后自己开酒吧吗?唱得还行但是不论是选歌品位还是装修品位都堪忧呀(我又在judge别人啦)
他终于尽兴了,换我上去,唱了啥我已经忘了,好像没唱多久,主理人和小绿就说想唱,我无所谓,我只想早点回家了。就把舞台又让给他们。
此时,我已经分不清楚这些行为的性质,这到底是在表演,还是在KTV自嗨,还是在干什么啊?增增哇嘎奶。
他俩嗨得不行,又是蹦又是吼的,我在后边坐着,心想还没结束啊。很累,也很无聊。二手烟也没有散去。我用手机搜索回家打车需要多久。
后来某首歌是主理人自己唱,然后小绿找我聊天,加了微信,他说有个新开业的酒吧找他,问我有没有兴趣驻唱。我说在哪,他说还没开呢。
他说他唱一三五,我唱二四六,怎么样,问我有没有兴趣。我说这个频率对我来说可能有点太高。
如果这个地方太远,我就不想去。驻唱还要应付点歌,什么都得会,不然别人点歌你怎么办。但是我不想学,学个鼓楼已经让我很痛苦。另外就是二手烟的问题。
可以看出,我虽然没什么水平,但十分挑剔,很难伺候。
我说,你要是哪天没空我可以偶尔帮你代代班吧。(开了个空头支票)总之就这么加上了微信,但没有聊过天。
主理人嗨完了,时间其实也差不多到了第三趴结束的时候,他问我你还唱吗,要不再唱一个。
我说好啊,(其实我内心是想唱一个开到荼蘼的,咋的不许我过瘾?),于是就唱了。不知道第多少次地想,这个歌词写得真好。
唱完了他们也没啥反应,气氛从冷冻室变成了太平间。可能都累了吧。
收拾东西回去,主理人开车,小绿骑电动车,我打车。还互相问了下大概的位置,说看看能不能捎一段,我说没事我打车。他们说等我坐上车再走。
没想到,我刚提交打车订单就叫到车了,车距离我——五十米。抬头一看,就在拐角处。于是匆匆拜拜了就上了车。
车子上了五环(或者四环,我不知道),窗外乌漆嘛黑,偶尔闪过一些建筑物,发光的标牌掠过我的眼睛。
迷茫,像夜空一样无边无际的迷茫向我涌来。我问自己,今天这算是怎么回事呢?
掏出手机,看到鼓手发来好友申请。加上之后,他说:
吉他手老师,希望以后可以多多合作!
我又翻了个白眼,回复他:头像有吉他的人就一定是吉他手吗?
他说,啊,那你是哪位老师?
我说我是主唱!
(完)